

Scaling Challenges: The Need for Multi-Layer Monitoring
Modern hosting providers manage vast infrastructure environments, often operating hundreds to thousands of Linux and Windows servers. These platforms support a wide range of services, including shared hosting accounts, SaaS applications, e-commerce platforms, enterprise APIs, and cloud workloads—making reliability and performance critical.
Downtime can have serious financial and operational impacts. For mid-size businesses, the average cost of downtime exceeds $5,000 per minute, while enterprise-level outages can result in even greater losses. Beyond financial damage, even brief disruptions can affect thousands of websites and harm brand reputation.
To minimize such risks, hosting companies deploy advanced monitoring systems that continuously track infrastructure health, network activity, application performance, and security threats. These systems operate across distributed data centers and cloud environments, delivering real-time visibility into server performance.
Within environments supported by Linux and Windows server management, VPS management, and dedicated server support, engineers implement multi-layer monitoring frameworks designed to detect anomalies within seconds.
This blog explores how hosting providers efficiently monitor large-scale server environments, the technologies and architectures involved, and how system administrators proactively resolve issues before they escalate into downtime.
Quick Summary: How Hosting Providers Monitor Thousands of Servers
Large hosting providers rely on centralized monitoring platforms powered by distributed agents, automated alerting systems, and 24/7 Network Operations Centers (NOCs).
These systems collect real-time metrics—such as CPU usage, memory utilization, disk performance, network traffic, application logs, and service availability—and analyze them to detect anomalies. Alerts are triggered whenever predefined thresholds are exceeded.
By combining proactive server monitoring, cloud infrastructure monitoring, and automated incident response workflows, infrastructure teams can resolve issues before they affect customers.
In high-availability environments, monitoring platforms integrate with maintenance systems, DevOps workflows, and managed cloud services, enabling engineers to manage thousands of servers from a single dashboard.
Why Monitoring Thousands of Servers Is a Complex Task
While monitoring a single server is relatively simple, managing thousands across multiple regions, operating systems, and cloud platforms introduces significant complexity.
Typical infrastructure includes:
-
Shared hosting servers (cPanel/WHM environments)
-
Enterprise Windows server environments
-
VPS-based hosting platforms
-
Dedicated server infrastructure
-
Hybrid and multi-cloud deployments (AWS, Azure, Google Cloud)
Each system generates massive volumes of performance data. Without automation, identifying issues in time becomes nearly impossible.
Modern monitoring systems track:
-
Resource utilization
-
Disk I/O performance
-
Database response times
-
Network latency and packet loss
-
Service uptime
-
Application errors
-
Security anomalies
With robust monitoring and system administration frameworks, engineers can automatically detect and resolve issues before they escalate.
How Server Monitoring Systems Work
Server monitoring platforms operate through a combination of agents, collectors, monitoring engines, and alerting systems.
Lightweight agents installed on servers continuously gather key metrics such as CPU load, memory usage, disk performance, running processes, and application logs. This data is transmitted to centralized platforms for real-time processing and analysis.
Engineers use monitoring dashboards to maintain a unified view of infrastructure health across thousands of systems. These dashboards typically display:
-
Server performance graphs
-
Resource utilization trends
-
Application uptime metrics
-
Network health indicators
When anomalies are detected, alerting systems notify engineers via email, SMS, or incident management tools.
Advanced environments often integrate monitoring with automated remediation scripts, allowing common issues to be resolved instantly.
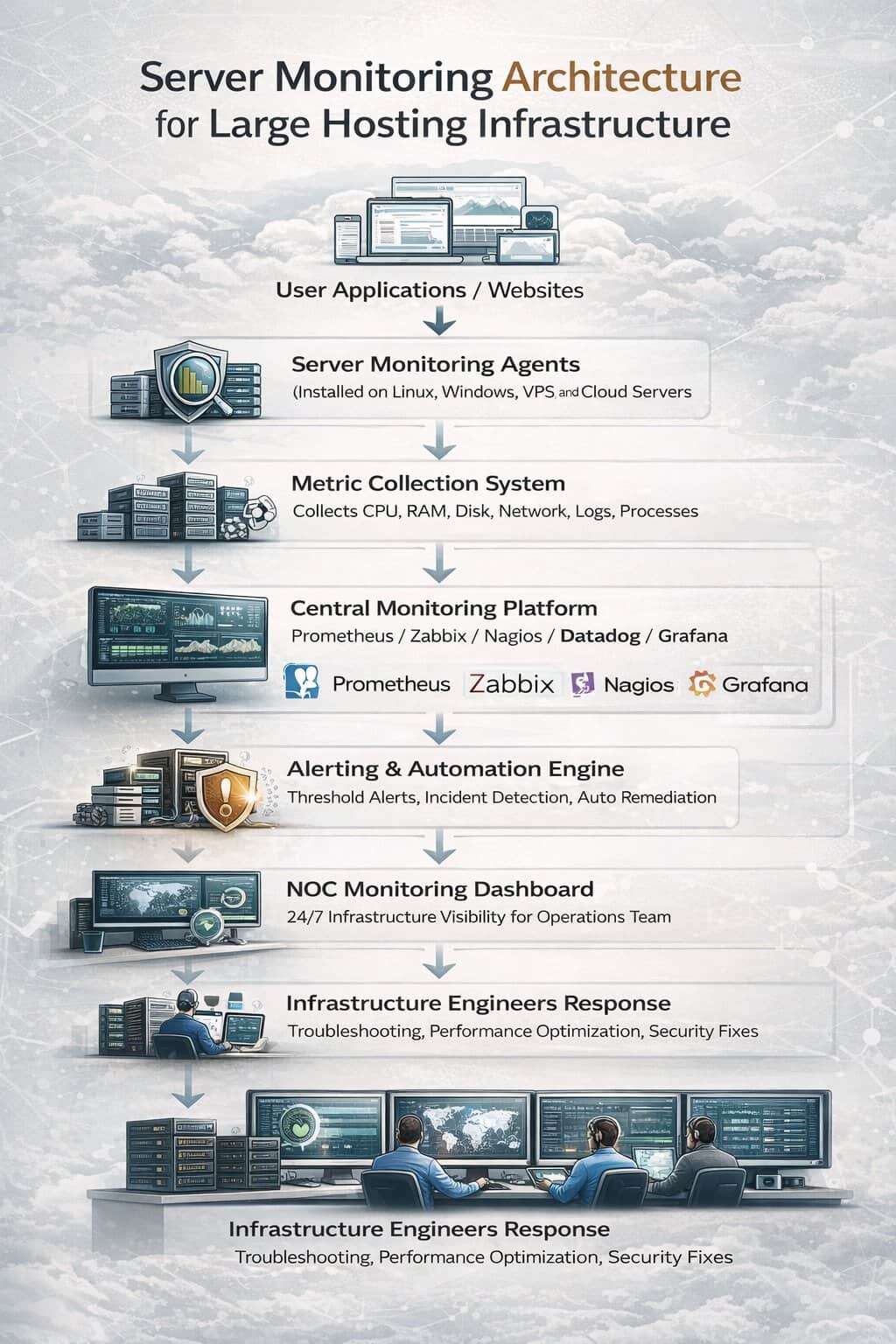
Monitoring Architecture Used in Large Hosting Platforms
Large-scale hosting providers implement layered monitoring architecture designed for scalability and reliability.
The architecture typically includes four core components.
Monitoring Agents
Monitoring agents run on every server and collect system data.
These agents track CPU usage, disk I/O, network activity, running services, and application performance.
In hosting environments that rely on cPanel server support services and Plesk server management services, agents also monitor control panel services such as Apache, MySQL, Exim, and FTP servers.
Central Monitoring Server
Collected data is transmitted to a centralized monitoring platform.
Popular monitoring platforms include:
- Prometheus
- Zabbix
- Nagios
- Datadog
- Grafana
These systems aggregate metrics from thousands of servers and provide dashboards that help engineers quickly identify issues.
Platforms used in cloud server management services and AWS server monitoring and management service environments often integrate monitoring with cloud-native telemetry services.
Alerting and Incident Response
Monitoring systems include automated alerting mechanisms that notify engineers when system thresholds are exceeded.
For example:
- CPU usage exceeding 90 percent
- Disk space nearing capacity
- Database latency increasing
- Network packet loss detected
Alert notifications allow infrastructure engineers to troubleshoot problems before they affect customers.
Organizations using proactive server monitoring services and server performance optimization services rely heavily on intelligent alerting to maintain high uptime.
Network Operations Center (NOC)
Most large hosting companies operate a 24/7 Network Operations Center responsible for monitoring infrastructure around the clock.
NOC engineers analyze monitoring alerts, investigate anomalies, and respond to incidents immediately.
Companies that use NOC support services and outsourced NOC support for hosting providers benefit from continuous monitoring without expanding internal teams.
Real-World Scenario: Detecting a Server Performance Issue
Consider a hosting provider managing several hundred shared hosting servers running cPanel server management and WHM server management services.
One evening, the monitoring platform detects unusually high disk I/O latency on a server, indicating a deviation from normal performance levels.
An alert is immediately triggered as disk response time rises significantly beyond expected thresholds.
Using the monitoring dashboard, engineers quickly investigate the issue and identify a backup process consuming excessive disk resources.
To prevent service degradation, the operations team pauses the backup task and redistributes workloads across other storage nodes.
Thanks to early anomaly detection, customer websites remain fully operational without any disruption.
This scenario illustrates how effective server monitoring, maintenance, and system administration services enable hosting providers to proactively prevent downtime.
Monitoring in Cloud and Multi-Cloud Infrastructure
Hosting infrastructure is no longer limited to physical servers. Many providers operate hybrid cloud environments spanning multiple platforms.
Infrastructure teams must monitor:
- Cloud virtual machines
- Container workloads
- Kubernetes clusters
- Distributed databases
- Serverless functions
Organizations providing managed cloud support services, AWS server management support, Azure cloud support services, and Google Cloud server support integrate monitoring with cloud-native tools.
These include services such as:
- AWS CloudWatch
- Azure Monitor
- Google Cloud Operations Suite
Monitoring tools collect telemetry data across multiple regions and provide unified dashboards.
In modern environments supported by multi cloud infrastructure management and cloud infrastructure monitoring services, engineers must monitor both physical and virtual infrastructure simultaneously.
Best Practices Used by Infrastructure Engineers
Experienced infrastructure engineers follow a set of best practices to efficiently monitor large-scale server environments.
Monitoring must be proactive rather than reactive, as relying on customer-reported issues indicates a failure in the monitoring process.
Equally important is the careful tuning of alert thresholds—excessive alerts can lead to fatigue, while insufficient alerts may allow critical issues to go undetected.
Incorporating predictive analytics further strengthens monitoring by identifying abnormal trends before they evolve into performance problems.
A well-structured infrastructure also integrates server patch management, along with hardening and security practices, to prevent vulnerabilities from impacting system stability.
Finally, effective monitoring includes robust backup and disaster recovery mechanisms, ensuring that critical data remains protected even during unexpected failures.
Why Many Hosting Providers Outsource Monitoring
Maintaining 24/7 infrastructure monitoring requires dedicated teams and significant operational resources.
Many hosting companies therefore partner with an outsourced web hosting support company that provides round-the-clock infrastructure monitoring.
Organizations offering white label web hosting support services, outsourced help desk support, and hosting support for hosting companies provide expert monitoring without requiring internal staffing expansion.
These providers often maintain dedicated operations teams that deliver:
- 24/7 infrastructure monitoring
- Incident response and troubleshooting
- Performance optimization
- Infrastructure security management
Companies relying on technical support outsourcing for SaaS companies and 24/7 technical support outsourcing gain access to experienced engineers capable of managing large hosting environments efficiently.
Infrastructure Statistics Highlighting Monitoring Importance
Industry data highlights the importance of effective monitoring.
Studies indicate that over 70 percent of infrastructure outages are caused by undetected system anomalies or misconfigured resources.
Organizations that implement proactive monitoring reduce downtime by nearly 40 percent compared to reactive support models.
Linux continues to dominate hosting infrastructure, powering more than 90 percent of public cloud workloads, making managed Linux server support services essential for modern hosting platforms.
Additionally, research shows that companies using centralized monitoring systems resolve incidents three times faster than those relying on manual monitoring processes.
Frequently Asked Questions
How does server monitoring work?
Server monitoring works by installing monitoring agents on servers that collect system metrics such as CPU usage, memory consumption, disk performance, and network traffic. These metrics are transmitted to centralized monitoring platforms where engineers analyze infrastructure performance and receive alerts when abnormalities occur.
What causes server downtime in hosting infrastructure?
Common causes include hardware failures, software bugs, resource exhaustion, network congestion, and security attacks. Effective server monitoring and maintenance systems help detect these issues early.
How do engineers troubleshoot Linux server performance issues?
Engineers analyze system logs, CPU utilization, memory usage, disk performance, and running processes. Tools such as top, iostat, and monitoring dashboards help identify bottlenecks quickly.
Why do hosting companies outsource technical support?
Outsourcing allows hosting providers to maintain continuous infrastructure monitoring and rapid incident response without hiring large internal teams. Providers offering white label hosting technical support and outsourced infrastructure support teams help ensure reliable service delivery.
Losing Clients to Slow Servers and Ticket Backlogs?
Partner with our L1–L3 hosting support specialists for 24×7 ticket and chat coverage, proactive server monitoring, and reliable uptime — so you can focus on growing your hosting business.
Talk to a Specialist
Conclusion
Monitoring thousands of servers efficiently requires sophisticated infrastructure architecture, real-time analytics, and highly skilled engineering teams. Hosting providers rely on advanced monitoring tools, automated alerting systems, and centralized dashboards to maintain visibility across complex server environments.
Through proactive monitoring strategies, infrastructure engineers can detect performance issues early, optimize system resources, and prevent downtime before it impacts customers.
Organizations that combine Linux server management services, cloud server management services, proactive server monitoring services, and managed cloud infrastructure support services are better equipped to maintain stable, high-availability hosting platforms.




