

Introduction:
Modern websites and SaaS platforms operate in an environment where traffic patterns can change within seconds. A marketing campaign, viral social media post, or seasonal event can suddenly generate thousands of concurrent users. Without a scalable infrastructure strategy, these traffic spikes often result in server overload, application crashes, and website downtime.
For infrastructure engineers responsible for maintaining high availability systems, cloud auto-scaling has become one of the most effective mechanisms for preventing downtime. Instead of relying on fixed server capacity, auto-scaling dynamically adjusts computing resources in response to real-time demand.
In large-scale hosting and application environments, this capability significantly improves reliability. Organizations that implement cloud auto-scaling alongside server monitoring and maintenance, proactive server monitoring services, and managed cloud infrastructure support services can maintain stable performance even during unpredictable workload spikes.
This article explains how cloud auto-scaling works, why it prevents downtime, and how experienced infrastructure teams implement it in real production environments.
Quick Summary: How Cloud Auto-Scaling Prevents Website Downtime
Cloud auto-scaling reduces downtime by dynamically increasing or decreasing server capacity based on system load and traffic demand. When demand rises, additional cloud instances are automatically launched to distribute traffic. When demand decreases, extra instances are removed, ensuring efficient resource utilization.
This approach reduces the risk of server overload, improves application availability, and ensures better uptime for websites and online services. When combined with cloud infrastructure monitoring services, server performance optimization services, and backup and disaster recovery support, auto-scaling becomes a critical component of modern high-availability cloud architecture.
Understanding What Causes Website Downtime
Website downtime rarely occurs due to a single factor. Instead, it usually results from infrastructure limitations, sudden workload spikes, or configuration issues.
One of the most common causes of downtime is resource exhaustion. Servers have finite processing capacity, and when traffic exceeds CPU, memory, or disk performance limits, applications begin to slow down or fail entirely. Engineers frequently observe high load averages, memory exhaustion, or slow database queries during such incidents.
Another major cause of downtime is sudden traffic spikes. Events such as product launches, flash sales, or viral marketing campaigns can rapidly increase website visitors. Without scalable infrastructure, the server may become overwhelmed.
Infrastructure misconfiguration can also lead to instability. Improper tuning in environments using cPanel server management, WHM server management services, or Plesk server management services may result in inefficient resource usage or service failures.
Finally, hardware or instance failures can cause outages if redundancy is not implemented. Cloud auto-scaling helps mitigate several of these risks by automatically provisioning additional computing capacity when required.
What Is Cloud Auto-Scaling?
Cloud auto-scaling is a cloud infrastructure capability that automatically adjusts the number of active server instances based on real-time workload demands.
Instead of running applications on a single server, modern systems distribute workloads across multiple instances within a scalable cloud environment. When monitoring systems detect increased load, additional instances are launched automatically to handle traffic. When demand decreases, excess servers are removed.
This elasticity allows organizations to maintain optimal performance without permanently over-provisioning resources.
Major cloud platforms provide built-in auto-scaling capabilities. AWS server management support uses Auto Scaling Groups, Azure cloud support services provide Virtual Machine Scale Sets, and Google Cloud server support includes Managed Instance Groups.
These platforms continuously monitor infrastructure metrics such as CPU usage, network throughput, and request rates to determine when scaling events should occur.
How Cloud Auto-Scaling Works in Real Infrastructure
In practical server environments, auto-scaling relies on several key infrastructure components working together.
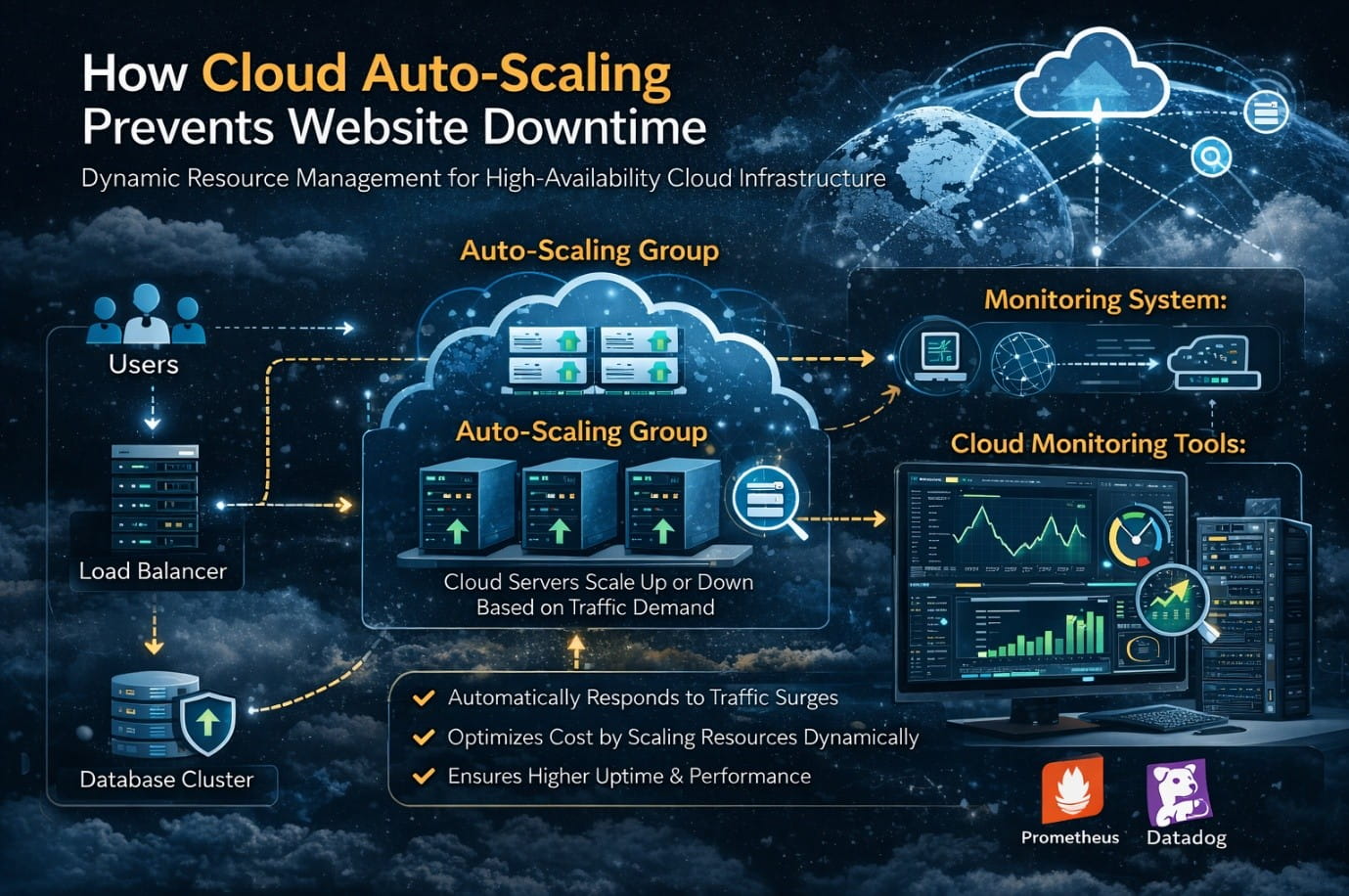
The first component is the load balancer. Load balancers distribute incoming traffic evenly across multiple server instances. Instead of all requests hitting a single server, the load balancer intelligently routes traffic across available infrastructure nodes.
Monitoring and scaling policies form the second critical component. Cloud monitoring tools track metrics such as CPU utilization, request rate, and memory usage. When predefined thresholds are reached, the auto-scaling system automatically launches additional servers.
Another essential component is instance templates. Infrastructure engineers create standardized templates containing operating system configuration, application deployment settings, security policies, and network rules. Every new server created during scaling uses this template, ensuring consistent infrastructure across all instances.
Real-World Example: Traffic Surge During a Product Launch
Consider a SaaS platform preparing for a new product release. Under normal conditions, the platform operates on two web servers that support several hundred concurrent users. CPU utilization typically remains around thirty to forty percent.
When the company announces the product launch, thousands of users attempt to access the platform simultaneously. Without scalable infrastructure, CPU usage quickly reaches one hundred percent. Database connections become saturated, and users experience slow responses or connection failures.
In an auto-scaling environment, monitoring systems detect the increase in load and automatically launch additional server instances. A load balancer distributes incoming traffic across these servers, ensuring no single machine becomes overloaded.
As traffic decreases later, unnecessary instances are automatically removed, reducing operational costs while maintaining service stability.
Auto-Scaling in Multi-Cloud Infrastructure
Large organizations increasingly deploy applications across multiple cloud providers to enhance reliability and geographic availability.
This approach, known as multi cloud infrastructure management, distributes workloads across providers such as AWS, Microsoft Azure, and Google Cloud. If one region or provider experiences issues, traffic can be redirected to alternative infrastructure.
When combined with managed cloud support services and DevOps infrastructure support services, multi-cloud architectures enable organizations to maintain high availability across global markets.
For example, user traffic in North America may be served by an AWS cluster, while European traffic is handled by Azure infrastructure. Backup capacity may exist within Google Cloud for additional redundancy.
The Role of Monitoring in Auto-Scaling Environments
Auto-scaling cannot function effectively without continuous monitoring. Proactive server monitoring services provide real-time insights into infrastructure health, enabling scaling policies to respond accurately to workload changes.
Monitoring tools analyze metrics such as CPU usage, memory utilization, disk performance, and network activity. Engineers also monitor application-level metrics like response time and request throughput.
Tools commonly used by infrastructure teams include Prometheus, Grafana, AWS CloudWatch, and Datadog. These platforms help engineers visualize system performance and detect anomalies early.
Organizations offering system administration services and cloud server management services rely heavily on monitoring automation to maintain infrastructure stability.
Best Practices Infrastructure Engineers Use for Auto-Scaling
Experienced infrastructure engineers follow several design principles when implementing auto-scaling systems.
Applications should be designed as stateless whenever possible. Stateless architecture allows any server instance to process user requests without relying on local session data.
Health checks are another essential practice. Load balancers must regularly verify the health of each server instance and automatically remove unhealthy nodes from the traffic pool.
Infrastructure teams also optimize instance startup times to ensure new servers can begin handling requests quickly. Preconfigured images, containerized deployments, and automated configuration management help achieve this goal.
Security must also be maintained during scaling events. Infrastructure engineers rely on server hardening and security management practices along with server patch management services to ensure new instances meet security standards.
Case Scenario from a Hosting Environment
A hosting company managing hundreds of customer websites experienced repeated downtime during traffic surges. Their infrastructure relied on shared hosting servers using cPanel server support services and centralized database systems.
When traffic spikes occurred, server resources were quickly exhausted, affecting multiple hosted websites simultaneously.
The company transitioned to a scalable architecture using auto-scaling web nodes deployed in AWS along with a managed database cluster and load balancing infrastructure.
They also implemented outsourced NOC support for hosting providers along with proactive monitoring services.
Within three months, downtime incidents decreased significantly. Average website response times improved, and the hosting platform became capable of supporting much higher traffic levels without performance degradation.
Infrastructure Statistics Highlighting the Importance of Scalability
Industry data demonstrates how critical scalable infrastructure has become for modern businesses.
Studies indicate that ninety-eight percent of organizations report downtime costs exceeding one hundred thousand dollars per hour. Additionally, more than seventy percent of outages occur due to capacity limitations or configuration issues.
Linux continues to dominate cloud infrastructure, powering over ninety percent of public cloud workloads. These statistics highlight the importance of working with experienced Linux server administration support company teams and infrastructure engineers capable of managing scalable environments.
Cloud Auto-Scaling Architecture for High-Availability Websites
Struggling with Traffic Spikes and Downtime?
Partner with our experts for reliable cloud auto-scaling, proactive monitoring, and high-availability infrastructure solutions.
Conclusion
Cloud auto-scaling has become a foundational technology for preventing website downtime in modern digital infrastructure.
By dynamically adjusting computing capacity based on real-time demand, organizations can maintain stable application performance during traffic spikes while optimizing operational costs.
However, auto-scaling alone is not enough. Reliable infrastructure also requires proactive monitoring, optimized server configurations, security management, and disaster recovery planning.
Experienced infrastructure engineers specializing in managed cloud infrastructure support services, server monitoring and maintenance, and server performance optimization services play a crucial role in designing resilient systems.




